
NER的过去、现在和未来综述-过去
 |
|
 2019-05-17
2019-05-17
背景
命名实体识别(NER, Named Entity Recognition),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。

评价指标
使用实体级别的精确率、召回率、F1
本文主要讲解NER历史使用过的一些方法,如果更关注于现在使用功能的一些方法,可以参考:
基于词典和规则的方法
利用词典,通过词典的先验信息,匹配出句子中的潜在实体,通过一些规则进行筛选。
或者利用句式模板,抽取实体,例如模板"播放歌曲${song}",就可以将query="播放歌曲七里香"中的song=七里香抽取出来。
正向最大匹配&反向最大匹配&双向最大匹配。
原理比较简单,直接看代码:ner_rule.py
正向最大匹配:从前往后依次匹配子句是否是词语,以最长的优先。
后向最大匹配:从后往前依次匹配子句是否是词语,以最长的优先。
双向最大匹配原则:
覆盖token最多的匹配。
句子包含实体和切分后的片段,这种片段+实体个数最少的。基于机器学习的方法
CRF,原理可以参考:Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
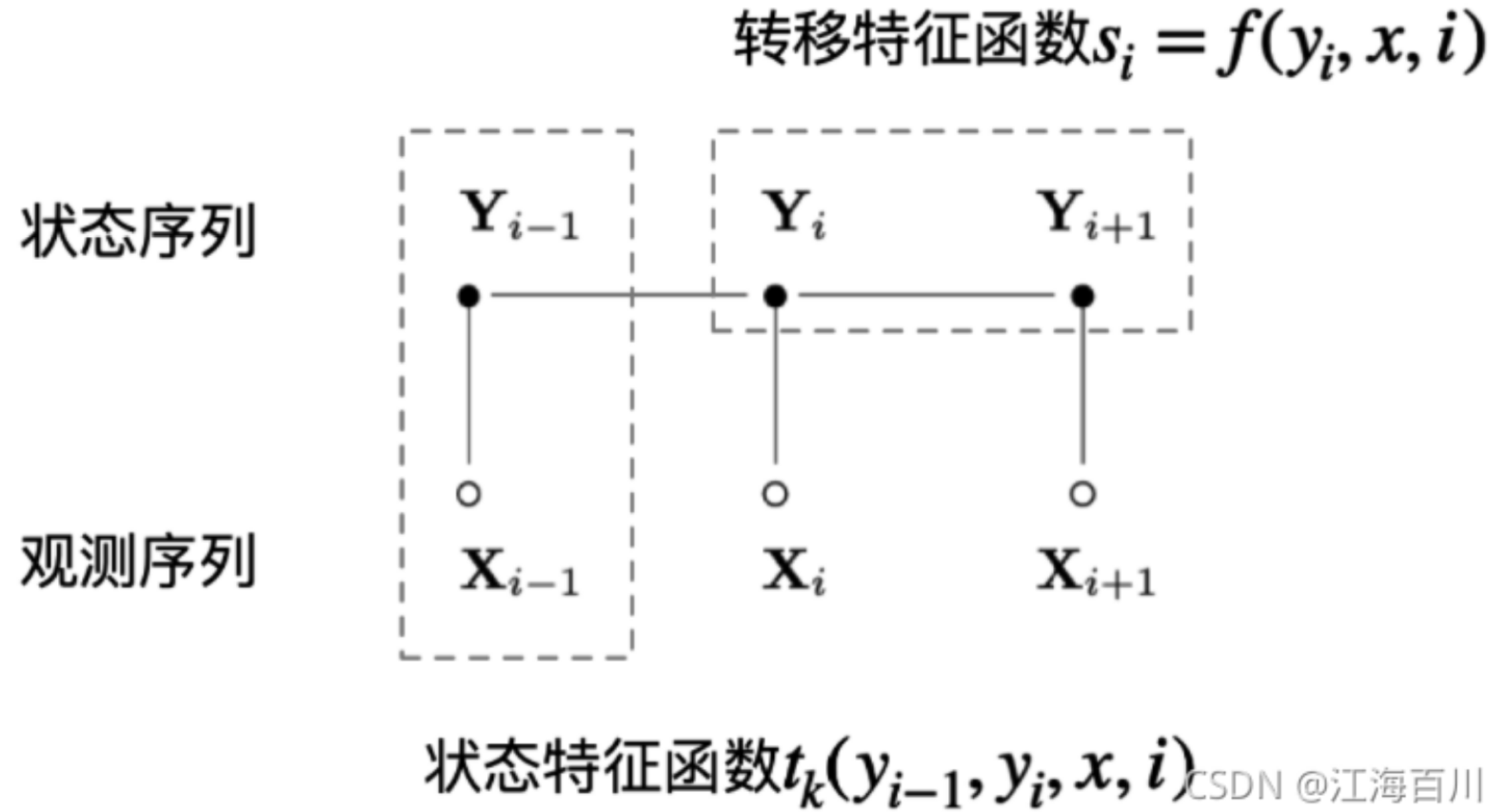
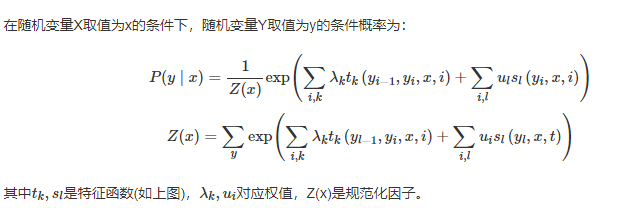
引入深度学习语义编码器
BI-LSTM + CRF
Bidirectional LSTM-CRF Models for Sequence Tagging
BI-LSTM-CRF 模型可以有效地利用过去和未来的输入特征。借助 CRF 层, 它还可以使用句子级别的标记信息。BI-LSTM-CRF 模型在POS(词性标注),chunking(语义组块标注)和 NER(命名实体识别)数据集上取得了当时的SOTA效果。同时BI-LSTM-CRF模型是健壮的,相比之前模型对词嵌入依赖更小。
文章对比了5种模型:LSTM、BI-LSTM、CRF、LSTM-CRF、BI-LSTM-CRF,LSTM: 通过输入门,遗忘门和输出门实现记忆单元,能够有效利用上文的输入特征。BI-LSTM:可以获取时间步的上下文输入特征。CRF: 使用功能句子级标签信息,精度高。
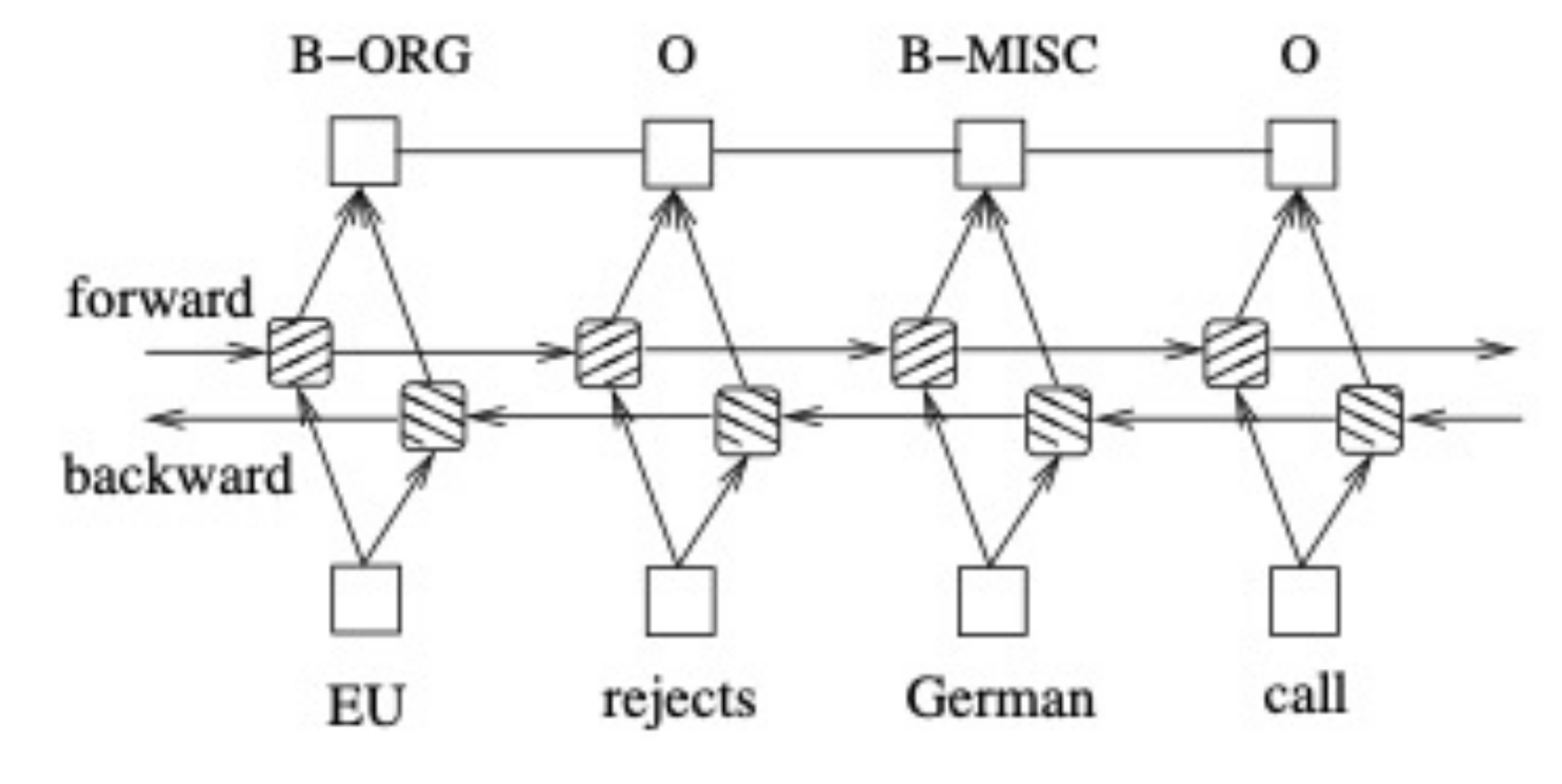
stack-LSTM & char-embedding
Neural Architectures for Named Entity Recognition
stack-LSTM :stack-LSTM 直接构建多词的命名实体。Stack-LSTM 在 LSTM 中加入一个栈指针。模型包含chunking和
堆栈包含三个:output(输出栈/已完成的部分),stack(暂存栈/临时部分),buffer (尚未处理的单词栈)
三种操作(action):
SHIFT: 将一个单词从 buffer 中移动到 stack 中;
OUT: 将一个单词从 buffer 中移动到 output 中;
REDUCE: 将 stack 中的单词全部弹出,组成一个块,用标签y对其进行标记, 并将其push到output中。
模型训练中获取每一步的action的条件概率分布,标签是真实每一步 action 的概率分布。预测时候,同坐预测每一步action概率,用概率最大action来执行action操作。
在REDUCE操作输出chunking块之后,通过lstm对其编码输出chunk的向量表达,然后预测其标签。
举例见图示:

同时使用初始化的char-embedding,对于每一个词语,通过BI-LSTM将字符编码作为输入,输出词语的字符级别表达,然后concat词向量输入到BI-LSTM + CRF。
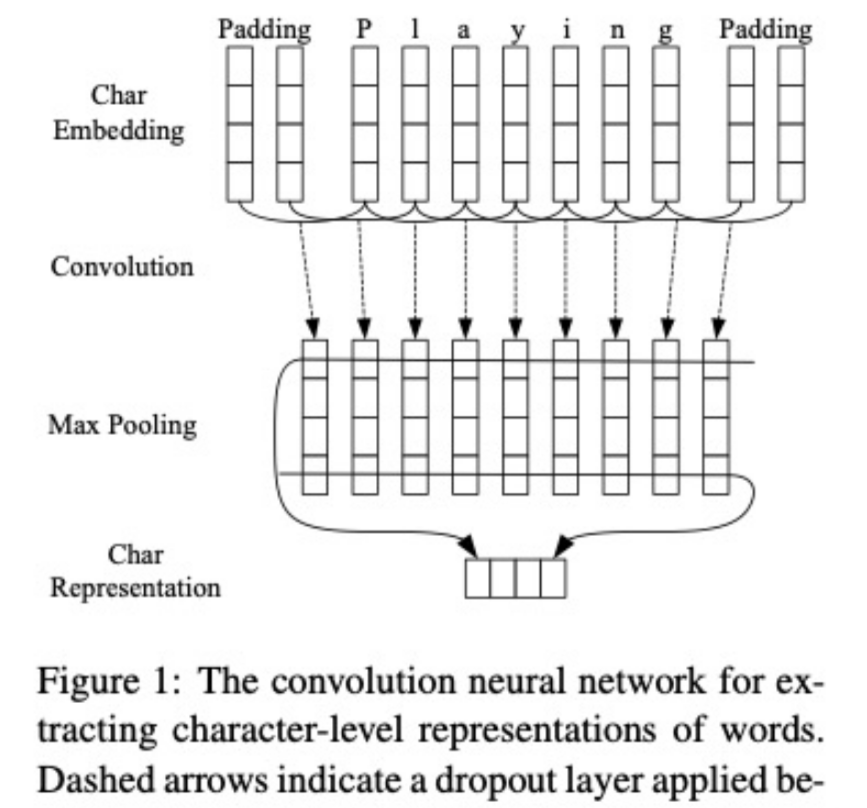
CNN + BI-LSTM + CRF
End-to-end Sequence Labeling via Bi-directional LSTM- CNNs-CRF
通过CNN获取字符级的词表示。CNN是一个非常有效的方式去抽取词的形态信息(例如词的前缀和后缀)进行编码的方法,如图。
编辑:航网科技 来源:腾讯云 本文版权归原作者所有 转载请注明出处

关注我们
 微信扫一扫关注我们
微信扫一扫关注我们
推荐阅读
