
一文入门eBPF
 |
|
 2019-05-17
2019-05-17
1. BPF的前世今生
bpf全称伯克利包过滤器(Berkeley Packet Filte),bpf技术诞生于1992年,早期主要用来提升对数据包的过滤性能,但是早期的bpf提供的指令较少,限制了它的应用范围。本文要介绍的ebpf是bpf的扩展版本,相比早期版本的bpf功能变得更加强大,自2014年引入内核以来,BPF现在已经成发展成内核中一个通用的引擎,通过相关API我们可以方便的读取到内核态的内存内容,也能够通过BPF改写运行时内存,具有强大的编程能力。毫不夸张的说,BPF技术就是内核中的脚本语言。
BPF的应用场景
BPF的应用场景非常广泛,总结下来主要有下面几大领域。
性能分析: BPF提供了对内核和应用程序极高的观察能力,通过编程可以实现比较丰富的统计功能,极高性能,能够避免对观测程序产生影响。
提高程序的观测性: 通过BPF技术,可以在函数调用的不同阶段进行插桩监控,能够观测运行时的程序内存,
通过提高程序的观测性,方便我们定位低概率复现的bug。
安全 : bpf技术能够观测系统系统调用,感知哪些进程在运行,哪些文件被改写,面对0day漏洞,也能够快速的编写出对应的检测程序。
除了上面列出的几个大的方向。K8s已经通过BPF技术来提高容器的网络安全性能和丰富的监控排错能力。甚至提供了基于Cilium的负载均衡能力。(k8s中用的是Cilium框架)
BPF的基本原理:
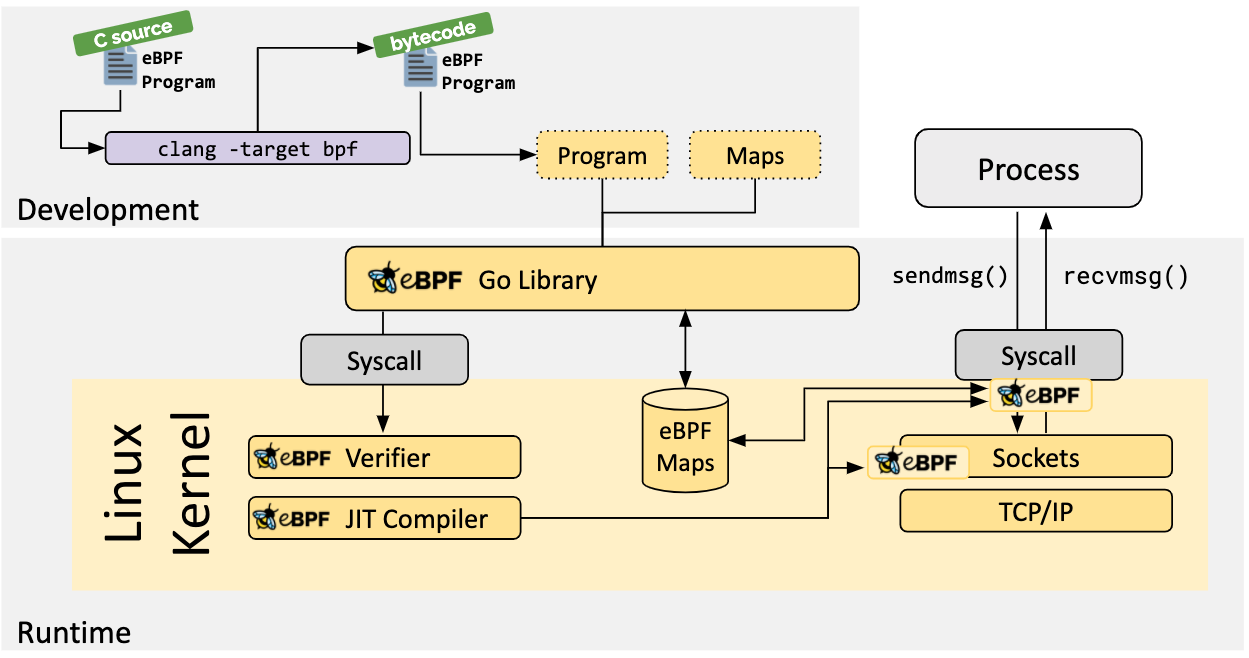
(引用:https://ebpf.io/what-is-ebpf#introduction-to-ebpf)
BPF程序首先由BPF验证器校验通过,再由编译器编译成特定的字节码。最后由运行在内核中的bpf虚拟机进行解释执行。内核也提供了一些helper函数,这里有详细的文档: https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
maps是eBPF提供的存储结构。我们可以使用maps进行统计,存储一些自定义变量,然后可以在用户态通过API读取这些数据。
BPF程序运行在沙箱当中,并且由验证器进行安全校验,可以防止bpf程序对系统造成破坏。如果在bpf程序中写了死循环,或者有数组越界的逻辑,验证器会直接报失败,防止程序对内核造成伤害。
如何编写ebpf工具?
目前有很多种工具(例如cilium, bcc, bpftrace),对bpf进行更高级的抽象,可以方便我们进行bpf程序开发。这些工具最终都会通过编译器编译成bpf的字节码。
安装bcc相关的编译工具

安装头文件

安装头文件
在 /usr/share/bcc/tools 这个目录下有很多已经写好的工具,这些工具是python写的,可以直接查看代码。这些工具保持了linux上工具一贯风格,所以使用起来比较简单, 这里不做过多描述。下面我们来看看具体如何编写BPF程序。
首先实现一个函数,输出一段字符串

接着编写一段BPF程序,通过对print_str函数进行插桩拦截,改写原本程序要输出的内容。

接着编写一段BPF程序,通过对print_str函数进行插桩拦截,改写原本程序要输出的内容。

通过ctx获取被跟踪函数的第一个变量,这里对应 print_str 函数的 char *s,如果有其他变量
则对应的改成 PT_REGS_PARM2,PT_REGS_PARM3

通过bpf_probe_read_user函数从用户空间读取数据到变量
bpf_trace_printk: 类似printf的功能,编写ebpf程序在debug时比较有用
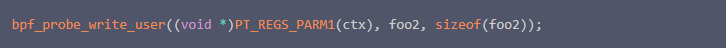
通过bpf_probe_write_user函数改写用户态的内容数据,这里直接将C程序中的foo2改成了zan

通过bpf_probe_write_user函数改写用户态的内容数据,这里直接将C程序中的foo2改成了zan
最后通过attach_uprobe高速bpf程序,需要跟踪用户态的程序时 a.out, 要跟踪的函数时 print_str, 以及对应的bpf处理函数时 change_msg
最后看效果:

编辑:航网科技 来源:腾讯云 本文版权归原作者所有 转载请注明出处

关注我们
 微信扫一扫关注我们
微信扫一扫关注我们
推荐阅读
